Webex Recordings Downloader Demo
November 15, 2024

From time to time there may be a need to download all Webex Meetings recordings. For example, to host them on an internal resource or to free up space on your Webex service. This blog post will go over how to bulk download years' worth of recordings locally using the Webex APIs and a Python application.
The APIs that are used to accomplish this are List Recordings For an Admin or Compliance Officer and Get Recording Details. The scopes required for these APIs are meeting:admin_recordings_read for an Admin or spark-compliance:meetings_read for a Compliance Officer.
How the Recordings Downloader Works
The Python application will need to be run twice. The first run will collect all recording IDs and the associated host email for the recordings and store the info in a .csv file. The second run will read the .csv file, query each recording to get the download link and then download the recordings to a folder called Downloaded-Recordings within the project folder. The app is broken into three Python files. The recording.py file is the main controller file and is what you would run to start the app. The list_recordings.py file is run when you choose option 1 and has the logic to collect all recording data and save it to a .csv file. The download_recordings.py file has the logic that reads the recording data from the .csv file and downloads the recordings locally.
On the first run you will be prompted to provide your access token. You can copy your personal access token from the Access the API doc page on the developer portal after you've logged in. The personal access token is meant for testing purposes and is only valid for 12 hours from the time that you login to the developer portal. This is what would be seen when running the app for the first time. Depending on how your Python installation is done you would either type python recordings.py or python3 recording.py to start the app.

After entering the access token it is stored in the token.json file and will be read from there for future API requests being made.
The code for this is:
tokenPath = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(tokenPath, 'token.json')
with open (filename, 'r') as openfile:
token = json.load(openfile)
bearer = token["token"]
if bearer == "":
print("No stored token. \nEnter your access token.\n")
token = input("> ")
while token == "":
print("No token entered. Try again.\n")
token = input("> ")
bearer = {"token":token}
with open('token.json', 'w') as updateToken:
json.dump(bearer, updateToken)
else:
print('Current Token: '+str(bearer))
Next the application will prompt to select options to either list recordings or download recordings. On the first run choose option 1 to collect recording data. There are also prompts to provide the meeting site URL and the number of weeks to pull for.
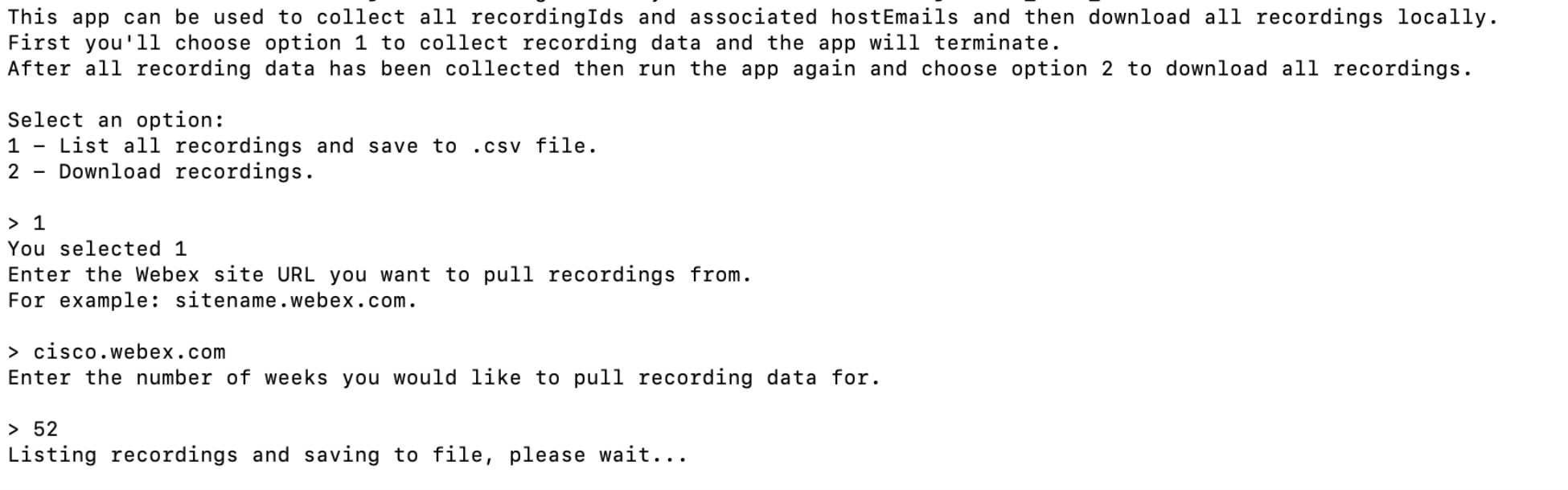
From here the list_recordings.py file is run. The API can return data for 30 days per request. The logic to handle this uses the datetime Python module to calculate 30 days before the current time and on each request, it will go back another 30 days until the number of weeks that were entered has been reached.
Initial to and from times are set using the following:
to_time = datetime.datetime.now().replace(microsecond=0)
from_time = to_time - datetime.timedelta(days=30)
end_time = from_time - datetime.timedelta(weeks=int(weeks))
After the request has completed then it will calculate new to and from times to make the next request with.
else:
to_time = from_time
from_time = to_time - datetime.timedelta(days=30)
The to time is set to the previous from time and then a new from time is calculated going back 30 more days. After this completes the application will terminate. Run it again and this time select option 2 and it will begin downloading all recordings that were pulled in the previous step. The logic for this is to read each row of the .csv file to get the recording ID and the host email and use that to construct the URL to get the recording details. It then reads the recordingDownloadLink from the response, which is the link to download the recording. The recording is downloaded and saved locally. This loops until there are no more rows to pull from the .csv file.
recordingDownloadLink = None
with open ('recordings.csv', 'r') as csvfile:
recs = csv.reader(csvfile)
for row in recs:
id = row[0]
hostEmail = row[1].replace('@','%40').replace("+", "%2B")
print("RecordingId: "+id+", HostEmail: "+hostEmail)
url = 'https://webexapis.com/v1/recordings/'+id+'?hostEmail='+hostEmail
result = requests.get(url, headers=headers)
downloadLink = json.loads(result.text)
links = downloadLink['temporaryDirectDownloadLinks']
recordingDownloadLink = links['recordingDownloadLink']
print("Download Link: "+recordingDownloadLink)
if recordingDownloadLink != None:
try:
recording = requests.get(recordingDownloadLink)
if recording.status_code == 200:
fileName = recording.headers.get('Content-Disposition').split("''")[1]
print("Filename: "+str(fileName))
with open("Downloaded-Recordings/"+fileName, 'wb') as file:
file.write(recording.content)
print(fileName+" saved!")
elif recording.status_code == 429:
retry_after = recording.headers.get("retry-after") or recording.headers.get("Retry-After")
print("Rate limited. Waiting "+str(retry_after)+" seconds.")
time.sleep(int(retry_after))
else:
print("Unable to download, something went wrong!")
print("Status Code: "+str(recording.status_code))
except Exception as e:
print(e)
else:
print("something went wrong.")
Optional Step: Create an Integration
You can also create an Integration and use it to generate a longer life access token as well as a refresh token. The refresh token can be used to programmatically generate and store a new access token if the current one expires. This application is capable of handling token refreshes by adding the integration's client_id, client_secret and refresh_token to the .env file. If the current token stored in the token.json file has expired the application will use the details in the .env file to generate a new access token. The logic to generate a new access token is controlled by the HTTP status code that's returned. If the status code is a 401, which would mean the current access token is no longer valid, then the app will attempt to generate a new access token and store it.
Get the Code
The full code for this demo application can be found at https://github.com/WebexSamples/WebexRecordingsDownloader.
Need Some Help? We Got You Covered!
This is provided as a demo with no warranty. If you need help, the Webex Developer Support Team is standing by and happy to assist. You can also start or join a conversation on the Webex for Developers Community Forum.