Deciphering Topic Modeling Evaluation in Webex Contact Center: Exploring Clusters and Label
April 2, 2024

Prasad N Kamath, Director, Software Engineering, was a contributor to this blog.
In Webex Contact Center, where a vast amount of customer interactions occurs through various channels like phone calls, and multiple digital channels, topic modeling plays a crucial role in optimizing the operations, enhancing agent performance, and ultimately delivering a more satisfactory customer experience in various ways. Dive into the depths of topic modeling where unsupervised machine learning unveils hidden patterns in vast textual data, from understanding its core principles to navigating complex evaluations, clusters, and natural language labels. The importance of topic model evaluation cannot be overstated as it serves as a critical step in ensuring the effectiveness and reliability of the generated models. Explore the challenges of subjectivity in evaluation and the crucial collaboration needed among experts. With a blend of quantitative metrics and qualitative assessments, discover how various types of topic modeling evolve as an indispensable tool, contributing to knowledge extraction. The blog unveils the challenges, intricacies, and interdisciplinary collaboration required for meaningful insights into the dynamic landscape of natural language processing.
Introduction
In the ever-expanding landscape of natural language processing, the quest to extract meaningful information from vast datasets has led to the prominence of topic modeling. Topic modeling is an unsupervised machine learning method that is utilized to categorize, understand, and summarize large collections of textual information. It helps in discovering hidden thematic structures in a vast corpus of text, enabling researchers to discern patterns in unstructured data. The role of topic modeling in Webex Contact Center is pivotal in enhancing operational efficiency and customer satisfaction. The integration of topic modeling in Contact Center brings about a paradigm shift in how customer interactions are managed. However, the effectiveness of a topic model is not solely determined by its ability to extract topics but also by how well those topics are evaluated, organized into clusters, and assigned natural language labels. Evaluating the effectiveness of topic models, understanding topic clusters, and generated topic labels can be a daunting task where the nuances of topic clusters, and crafting natural language topic labels pose intricate challenges. This blog aims to simplify these concepts, offering insights into how best to evaluate topic models and understand their outputs.
Understanding the relation between Topic Modeling and Contact Center
Before we delve into the evaluation of topic models, it is crucial to understand what topic modeling is all about. At its core, topic modeling identifies topics in a collection of documents and thus provides a structured representation of the content. It is based on the premise that each document comprises a mixture of topics, and each topic is a collection of words with certain probabilities which can also be represented by a well-formatted natural language label. Internally, the topic modeling algorithm mostly uses an unsupervised mechanism to form distinct clusters of textual information and then discovers the latent themes for each of them which gets further refined in the form of WordCloud or meaningful labels. Supervised processing can also be used in topic modeling with pre-discovered themes or categories. Guided topic modeling is one such pattern where both Supervised and/or Unsupervised approaches can be taken to model the topics.
In the context of Webex Contact Center and that way in any Contact Center solution, the role of topic modeling is pivotal in enhancing operational efficiency and customer satisfaction. Topic modeling augments the contact center in various ways:
- Automated Categorization: Topic modeling algorithms enable contact centers to automatically categorize and classify incoming customer queries or issues (as part of conversations). This automation streamlines the routing of inquiries to the appropriate departments or agents, ensuring a quicker and more accurate resolution.
- Agent Training and Knowledge Management: By analyzing customer interactions, topic modeling helps identify recurring issues, concerns, or frequently discussed topics. This information is invaluable for agent training and knowledge management. It allows contact centers to prioritize training on specific topics, ensuring that agents are well-equipped to handle common customer queries.
- Improving First Contact Resolution (FCR): Topic modeling aids in identifying the primary topics or issues raised by customers. This information empowers agents to address concerns promptly during the initial contact, thereby improving First Contact Resolution rates. Customers benefit from quicker issue resolution, leading to higher satisfaction levels.
- Enhanced Customer Experience: Understanding the topics that are most relevant to customers allows contact centers to tailor their services and communication strategies. This customization contributes to an enhanced overall customer experience, as customers feel understood and receive more personalized support.
- Monitoring Trends and Emerging Issues: Topic modeling enables contact centers to monitor trends and identify emerging issues in real time. By staying proactive and addressing emerging concerns promptly, contact centers can prevent potential escalations and demonstrate a commitment to customer satisfaction.
Thus, the integration of topic modeling in contact centers brings about a paradigm shift in how customer interactions are managed. By leveraging advanced algorithms to extract meaningful insights from textual data, contact centers can optimize their operations, enhance agent performance, and ultimately deliver a more satisfactory customer experience.
Understanding Topic Clusters and Generated Topic Labels
Topic clusters are groups of similar topics generated by the topic modeling algorithm. Topic modeling aids in summarizing large volumes of text by distilling the main themes into manageable clusters. It enhances search and retrieval systems by associating documents with relevant topics, improving the accuracy of information retrieval as well as facilitating efficient content management. Topic clusters can be visualized using Dimensionality Reduction methods like t-SNE and UMAP, which help in understanding the proximity and overlap between different topics.
Natural Language Topic labels, on the other hand, are the phrases that characterize a topic. They provide a succinct summary of the content represented by each topic cluster. These labels are generated by a Language Model based on the major keywords that have the highest probabilities (or likelihood) within each topic. The top words with the highest probabilities usually define the theme of the topic. The generated coherent labels represent the theme in a human-interpretable pattern which should also be cohesive to the topic cluster members.
Evaluation of Topic Modeling
The importance of topic model evaluation cannot be overstated as it serves as a critical step in ensuring the effectiveness and reliability of the generated models. Evaluation metrics help gauge how well the models perform on actual datasets and whether their outputs align with the goals of the specific application or task. Evaluating these models is essential for several reasons:
- Topic model evaluation helps validate the accuracy and appropriateness of the model in capturing meaningful topics within the given dataset. The evaluation should cover both quantitative and qualitative aspects of topic models and generated topics.
- Assessing the quality of topics generated by a model is crucial for its practical utility. Evaluation metrics help determine whether the identified topics are coherent, relevant, and distinct. This ensures that the model produces meaningful insights rather than hallucinated or irrelevant themes. Understanding and interpreting the results of topic models are crucial for practical applications. Evaluation metrics help assess the interpretability of topics, ensuring that the generated themes align with the expectations and requirements of end-users.
- Topic models contain parameters that influence their performance. Evaluation provides insights into the impact of different parameter choices on the model's effectiveness. Optimizing these parameters is essential for achieving the best possible results in terms of topic quality and coherence.
- Evaluation facilitates the comparison of different topic models or variations of the same model. Researchers and practitioners can use evaluation metrics to identify which model performs better in terms of topic quality, coherence, and applicability to specific tasks or domains.
- Evaluating topic models helps assess their robustness and stability across different datasets or variations in input parameters. A robust model should consistently perform well across diverse scenarios, providing reliable results.
Evaluating topic models can be challenging since it's mostly an unsupervised learning technique in the real world. Moreover, topic modeling algorithms mostly rely on mathematics and statistics. Mathematically we aim to reach a high intra-cluster (within-cluster) similarity and a low inter-cluster (between-cluster) similarity. However, mathematically optimal topics are not necessarily 'good' from a human point of view. For data understanding, the topics created need to be human-friendly. So, just blindly following the inherent math behind topic model algorithms can lead us to misleading and meaningless topics. There are various aspects that ought to be considered, such as Topic Cluster Composition, Topic Member Cohesion & Topic Cluster Separation, Topic Label Relevance, etc. On the other hand, qualitative human evaluation of topic modeling is also impracticable to very large datasets with thousands of topics. There are, however, several methods to evaluate the performance of topic models. Some of them are:
Topic Coherence: It represents the 'quality of human perception' about topics in an objective, and easy-to-evaluate number. It assesses how well a topic is 'supported' by a text set. It measures the semantic coherence of words within a topic. Higher coherence scores indicate more interpretable and meaningful topics. However, this method cannot correlate Natural Language Topic Labels with the member text set and instead works with keywords only.
Perplexity: It is also known as 'held out log-likelihood' as logarithm gets used to calculate it. The idea is to train a topic model using the training set and then test the model on a test set that contains previously unseen documents using its predictive ability. This metric does not provide good results for human interpretation.
Topic Diversity: It assesses the variety of topics generated. A diverse set of topics reflects a more comprehensive representation of the dataset.
Internal Validation: This evaluation mechanism uses internally available clustering information to assess the goodness of the clusters. Internal validation measures rely on the compactness and the separation of the cluster partitions. Predominantly most of the indices used in internal clustering validation combine compactness and separation measures.
- Silhouette Score: It represents the intra-cluster and inter-cluster variation. The Score can vary between -1 (incorrect clustering) and 1 (dense clustering). A score of 0 indicates overlapping clusters. It is higher when Topic Clusters are dense and well separated. Silhouette Score is more popular for Centroid-based clustering algorithms like K-Means (biased towards Spherical Clusters).
- Validity Index: This index is used in Density-based clustering. It assesses clustering quality using the relative density connection between pairs of objects. The Score can vary between -1 and 1 with higher values indicating a ‘better’ clustering. (it is different from relative validity which is a fast approximation-based score used to compare results across different combinations of hyper-parameters). This index can assess any number of arbitrarily shaped clusters.
- Miscellaneous Indices: Indices like the Dunn Index, DB Index, and CH (Calinski-Harabasz) Index are more useful for comparing various clustering models in Centroid-based Clustering.
In Density-based Clustering "Sample Probability" can also be used to assess the quality of the generated clusters. It shows the strength with which each sample becomes a member of its assigned cluster. Noise points have zero probability.
External Validation: It validates the clustering output against an external reference.
Manual Evaluation: This involves human evaluators who rate the quality and relevance of the topics generated along with the generated labels. It might be time-consuming but often provides the most reliable evaluation.
Evaluation of Topic Clusters and Topic Labels
Evaluating topic clusters and labels is largely a qualitative process. Here are some steps to follow:
- Diversity: Good topics should be different from each other. If many topics seem similar, it might signify an issue with the model, or the number of topics chosen.
- Completeness: A good topic should cover a concept or an idea completely. If a topic seems to cover more than one concept, it might indicate that the model isn't able to distinguish between them effectively.
- Understandability: Check if the topics make sense. Is the label in each topic properly representing the theme of the topic? Are the major keywords in each topic semantically related?
- Relevance: The topic labels (& in turn major keywords) should be relevant to the overall content of your corpus.
Challenges & Proposed Approach
Subjectivity in the evaluation poses a major challenge in Topic Modeling. Evaluating topic modeling goes beyond quantitative metrics as standard evaluation metrics may not always capture the subjective nature of topics. If a topic model is used for a measurable task, such as classification, then its effectiveness is relatively easier to calculate. However, if the model is used for a more qualitative task, such as exploring the semantic themes in an unstructured corpus, then evaluation is more difficult. It involves understanding the semantic coherence, diversity, and relevance of identified topics which suggests a combination of quantitative and qualitative assessments. On top of that, the generated Topic Clusters may not always take a 'Spherical shape'. Most of the time in the Contact Center world the clusters are of an 'Arbitrary' pattern due to the nature of the domain-specific conversations. While quantitative measures like various indices, probability, perplexity, and coherence are helpful, the qualitative evaluation of topic clusters and natural language labels by human annotators or equivalent still remains a reliable method of evaluation.
The following algorithm has laid out a similar mixed evaluation approach for the Centroid-based and Density-based clustering models where we have used a combination of interpretation-driven qualitative (akin to judgment-based) and quantitative approaches.
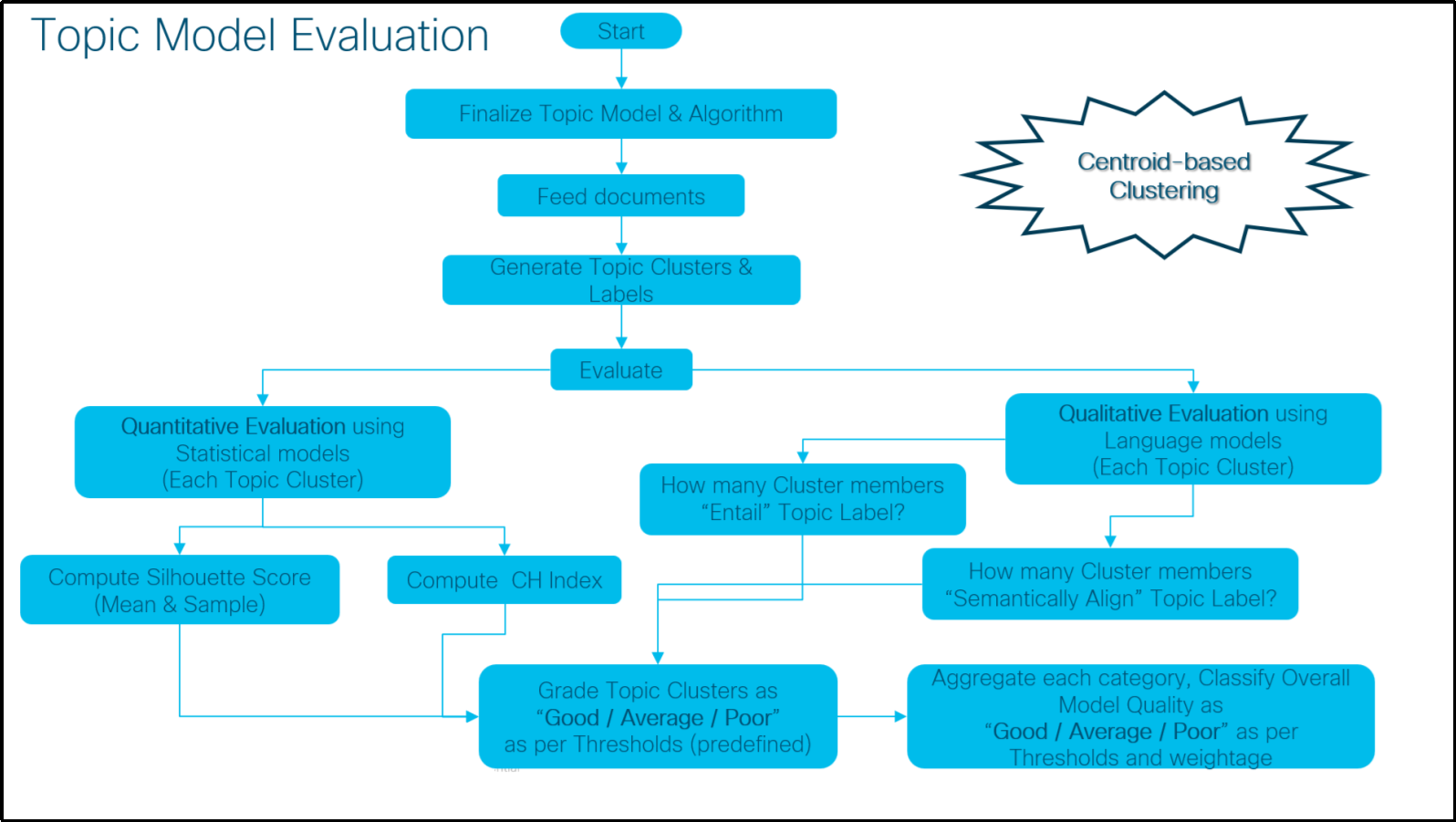
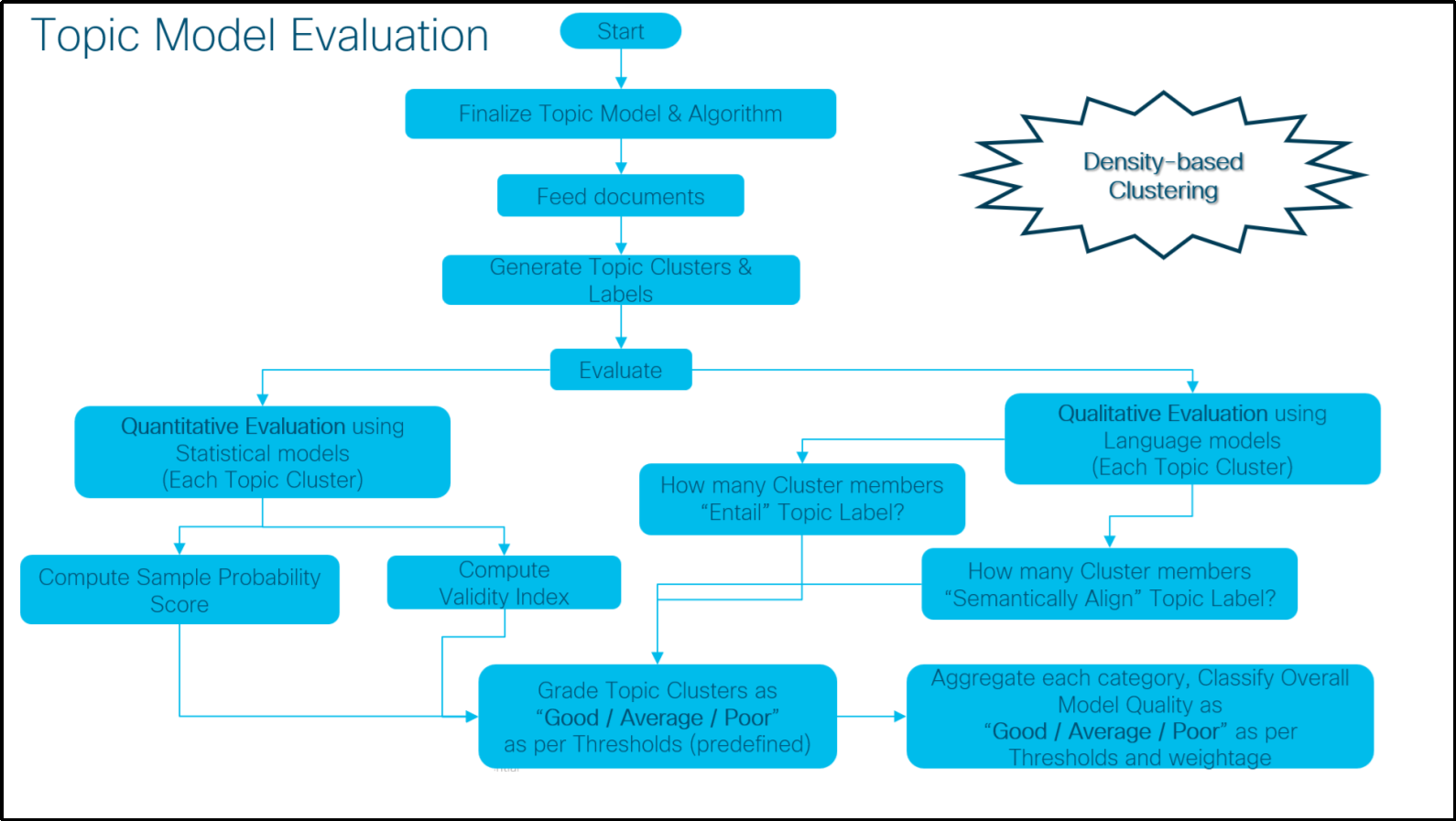
As part of the quantitative evaluation calculate the recommended score and index (as per the Clustering Model) for each topic cluster. The prescribed algorithm has already chosen the most appropriate set of metrics based on their popularity, applicability, and interpretability. Depending on the predefined configurable thresholds for each metric, the clusters have been graded accordingly.
During the qualitative assessment, we have used multiple pre-trained natural language models to calculate the cluster members' logical (aka Entailment) and semantic alignment (semantic similarity) with the respective topic label. Here also we have used configurable thresholds for both entailment score and angular similarity to grade the clusters.
Finally, we have aggregated all the categories as per configurable weighting of quantitative and qualitative assessments and graded the overall topic modeling.
Conclusion
Topic modeling is a powerful tool that assists in uncovering hidden structures in text data, and its evaluation, although challenging, is crucial for the success of your machine-learning project. The intricacies of topic modeling evaluation, topic clusters, and generated natural language topic labels highlight the interdisciplinary nature of this field. As technology advances, addressing these complexities becomes pivotal for the continued refinement of models and the extraction of meaningful insights from the ever-expanding sea of textual data. It mandates persistent collaboration between domain experts, linguists, and data scientists. Embracing the challenges, researchers and practitioners contribute to the evolution of topic modeling, making it an indispensable tool in the quest for knowledge and understanding within the vast realms of natural language processing. By leveraging advanced Topic Modeling algorithms, Contact Centers in turn can optimize their operations, enhance agent performance, and ultimately deliver a more satisfactory customer experience.